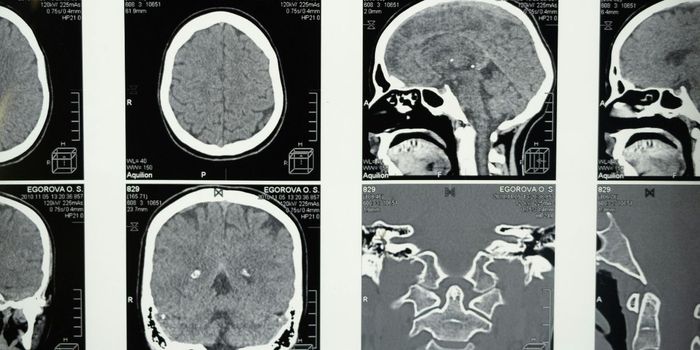
Songbirds are able to separate sounds by processing them according to two distinct categories- time and frequency. To understand whether humans are able to do the same, Robert Zatorre, a professor at McGill University, and his team, conducted a study looking at how humans distinguish between words and melodies in songs.
To do so, he first partnered up with a composer and a soprano, with whom he created 100 unique acapella songs from 10 sentences each sung alongside 10 original melodies for a few seconds each. Then, using a computer, he and his team altered the recordings. In some, they removed information regarding song frequencies, producing a breathy-sounding voice similar to that of Darth Vader. In others, they removed information about how the sounds changed over time, making the music sound more like someone humming than singing.
To understand how these interferences altered the processing of the sounds in the brain, they then invited 49 participants to listen to the melodies and words. In the end, they found that participants were still able to recognize the lyrics in the songs in which frequencies were changed, although they were unable to recognize the melodies. Meanwhile, in those in which timings were changed, participants were unable to understand the lyrics, although they were still able to recognize the melodies.
While listening to the songs, the researchers also recorded each participant's brain activity using a functional MRI. The results from these scans demonstrated that while speech content was primarily processed in the left auditory cortex, melodic content primarily activated the right cortex.
All in all, the study demonstrated that listening to music engages both hemispheres of the brain a way that is different from processing either music or speech by themselves. According to Zatorre, that may be why songs are especially easy to remember and carry special meaning across cultures around the globe.
Following these findings, the researchers hope to figure out how the brain combines both streams of information into coherent listening experiences. More than this, they also aim to study the same process in more melodic languages, such as Thai and Mandarin, to see how results may differ.
Sources: NPR and Science Mag